What's That Noise?! [Ian Kallen's Weblog]
 Saturday January 07, 2006
Saturday January 07, 2006
AJP13 for Ruby on Rails? Let's call the CGI specification what it is: a burned out and anemic teenager. While it seems kinda cool that Apache 2.2's is going to get mod_proxy_fcgi, I've long wondered about using AJP13 to interface with web application runtimes other than servlet containers.
Brian McCallister did a kick butt cut-to-the-chase preso on Ruby on Rails at ApacheCon in San Diego. I can imagine why he's gung-ho to get a FastCGI support upto date, it seems to be the the way to run RoR. But since learning that AJP13 was going to be (and now is) built in to Apache 2.2's mod_proxy framework, I've been thinking how much nicer it'd be for other application frameworks to also be able to run outside the HTTP request handling process/thread.
We have some services that run under mod_perl that I've been taking second (and third) looks at. Wouldn't it be nice to deploy that application independent of the HTTP server runtime as one can with a Java webapp? Essentially, when it's boiled down to bare metal, perhaps that's all FastCGI is but it, it... it's CGI! Isn't it just setting/getting global environment variables? STDIN/STDOUT/STDERR? Isn't that so, well, 1994? Maybe I need to think about it some more but that was my take away last time I built anything with FastCGI (admittedly, in the 1990's).
I found what looks like AJP13 protocol support for Perl. Even though I don't read Japanese I'll infer from the context that he was/is interested in the same thing. Though whenever I see "use threads" in Perl, I fear the worst. Anyway, the likelihood of me finding myself with the time on my hands to implement AJP13 in Ruby is low; first, I still need to learn Ruby enough to get crafty.
rubyonrails ruby java apache cgi fastcgi ajp13 perl mod_perl
( Jan 07 2006, 01:20:50 PM PST ) Permalink
Friday January 06, 2006
Open Source Language Detection No, not a typo. OSDL is something else. I'm interested in OSLD. I've used Language::Guess to detect languages in arbitrary text with Perl, it works pretty well. But how are folks solving the problem in Java?
It looks like Oracle has language detection as part of their "Globalization Development Kit" ... but what about open source? Sadly, the Nutch Language Identifier Plugin only supports European languages, no CJK. What are the other options?
opensource open source i18n language java perl nutch oracle
( Jan 06 2006, 02:22:54 PM PST ) Permalink
Thursday January 05, 2006
Regexp'ing simple XML I ran a test to prove to myself that for simple XML documents, the best way to parse them may be to skip capital P parsing altogether and just use a plain-old regular expression pattern match.
The XML format I wanted to test is the response from the Technorati /bloginfo API. I threw together a Perl based benchmark quickly enough and here are the results:
Benchmark: timing 10000 iterations of regexp, xpath...
regexp: 0 wallclock secs ( 0.13 usr + 0.00 sys = 0.13 CPU) @ 76923.08/s (n=10000)
(warning: too few iterations for a reliable count)
xpath: 137 wallclock secs (136.17 usr + 0.04 sys = 136.21 CPU) @ 73.42/s (n=10000)
... the regexp parse was three orders of magnitude faster than the XPath parse. I'm curious now what the comparison would be for Java's regexp support versus, say, Jaxen and JDOM (which is how I usually do XPath in Java). In my dabblings with timings, Java regexp's are very fast. Apparently, Tim Bray found this as well.
Here's the Perl code:
#!/usr/bin/perl
use XML::XPath;
use XML::XPath::XMLParser;
use XML::Parser;
use Benchmark qw(:all) ;
my $X = new XML::Parser(ParseParamEnt => 0); # non-validating parsing, please
timethese(10000, {
'xpath' => \&xpath,
'regexp' => \®exp
});
sub xpath {
my $b = getBlog();
my $parser = XML::XPath::XMLParser->new(parser => $X);
my $root_node = $parser->parse($b);
my $xp = XML::XPath->new(context => $root_node);
my $nodeset = $xp->find('/tapi/document/result/weblog/author');
die if ! defined($nodeset);
}
sub regexp {
my $b = getBlog();
my ($author) = $b =~ m{<author>(.*)</author>}sm;
die if ! defined($author);
}
sub getBlog {
return q{<?xml version="1.0" encoding="utf-8"?>
<!-- generator="Technorati API version 1.0 /bloginfo" -->
<!DOCTYPE tapi PUBLIC "-//Technorati, Inc.//DTD TAPI 0.02//EN" "http://api.technorati.com/dtd/tapi-002.xml">
<tapi version="1.0">
<document>
<result>
<url>http://www.arachna.com/roller/page/spidaman</url>
<weblog>
<name>What's That Noise?! [Ian Kallen's Weblog]</name>
<url>http://www.arachna.com/roller/page/spidaman</url>
<rssurl>http://www.arachna.com/roller/rss/spidaman</rssurl>
<atomurl></atomurl>
<inboundblogs>6</inboundblogs>
<inboundlinks>8</inboundlinks>
<lastupdate>2006-01-02 18:38:03</lastupdate>
<lastupdate-unixtime>1136255883</lastupdate-unixtime>
<created>2004-02-23 12:04:51</created>
<created-unixtime>1077566691</created-unixtime>
<rank>false</rank>
<lat>0.0</lat>
<lon>0.0</lon>
<lang>26110</lang>
<author>
<username>spidaman</username>
<firstname>Ian</firstname>
<lastname>Kallen</lastname>
<thumbnailpicture>http://static.technorati.com/progimages/photo.jpg?uid=11648</thumbnailpicture>
</author>
</weblog>
<inboundblogs>6</inboundblogs>
<inboundlinks>8</inboundlinks>
</result>
</document>
</tapi>
};
}
For some of the messaging infrastructure at Technorati where the messages are real simple name/value constructs, we've been passing on using XML at all. Using a designated-character-delimited format string (say, tabs) that can be rapidly transformed into a java.util.Map (or a Perl hash, a Python dictionary, yadda yadda yea) and passing messages that way buys a lot of cheap milage. We like cheap milage.
xpath regexp perl java messaging technorati
( Jan 05 2006, 11:26:28 AM PST ) Permalink
Wednesday January 04, 2006
Technorati Cosmos Links in Roller Now that I'm messing around with a roller implementation from within the last 7 months (migrated from Roller 0.98 to 1.1), I'm going to work on closing the gap to 2.0. Migrating all of my apps from an old (3.x) version of MySQL to 4.1.x wasn't too bad. But it appears that somewhere along the way to Roller 2.0, somewhere in the MySQL upgrade cycle perhaps, the post <-> category mappings got mangled and that was resulting in NPE's when the system tries to fetch the categories.
In the meantime, I implemented embedding cosmos links in my posts by patching WEB-INF/classes/weblog.vm (from the 1.1.2 release):
479,486c479 < #end < < #macro( showCosmosLink $entry ) < <a href="http://technorati.com/search/$absBaseURL/page/$userName/#formatDate($plainFormat $entry.PubTime )"><img < src="http://static.technorati.com/pix/icn-talkbubble.gif" < border="0" < title="Links to this Post" /></a> < #end --- > #endIn the velocity template, I just added:
#foreach( $entry in $entries )
<a name="$utilities.encode($entry.anchor)" id="$utilities.encode($entry.anchor)"></a>
<b>$entry.title</b> #showEntryText($entry)
<span class="dateStamp">(#showTimestamp($entry.pubTime))</span>
#showEntryPermalink( $entry )
#showCosmosLink( $entry )
#showCommentsPageLink( $entry )
<br/>
<br/>
#end
I think the POJO's and macros are different in 2.0 but I'll post a cosmos link update when I get there.
technorati roller velocity mysql
( Jan 04 2006, 07:29:26 AM PST ) Permalink
Monday May 16, 2005
Baking Components With Velocity For years I've advocated that heavyweight content generation should be moved out of the CMS and that publishing systems should do most their work asynchronously.
Recently, I've been generating Velocity components that should be evaluated at request-time but have at least some of the values they must work with calculated asynchronously when the component is generated. Here's an example that involves localizable content:
<div class="fubars">
$text.get("fubars.per.second", [ $fubarRate ])
</div>
So let's say the ResourceBundle has a key in it for fubars.per.second like so
fubars.per.second=Number of Fubars Per Second: {0}
If all of the calculation is done at request time, MessageTool would do its thing and this would Just Work. However, if $fubarRate is part of a heavier weight calculation that is done offline, we have to set it. So this is where I use Velocity to generate Velocity code:
#set($fr = '#set($fubarRate = ')
#set($fr = "${fr} $measurement.fubarRate)")
$fr
Notice the use of single quotes and double quotes to get the right combination of literal and interpolated evaluation. If my measurement object has a fubarRate property set to 42 then the last line simply outputs
#set($fubarRate = 42)and later, after the generated component gets its request time evaluation, the display is rendered as
<div class="fubars"> Number of Fubars Per Second: 42 </div>
Sure, I could generate my components with the web tier's ResourceBundle to get messages evaluated async as well. This would be 100% baking instead of 90% but it would be bad in other ways:
- It would create a cross dependency between the offline content generation framework and the web code. The ResourceBundle works fine on the web tier, I say leave it there.
- I would have to create another ResourceBundle evaluator for Velocity; MessageTool hooks into struts' plumbing for handling different Locale's, HttpServletRequest's and other container dependencies. Porting it to work outside of the web context seems like a waste of time; let the web tier be the web tier
This separation of baking versus frying ain't new. I advocated it a long time ago in a talk at the O'Reilly Open Source Conference. I was hot on mod_perl and HTML::Mason back then (and, given a Perl environment, I still like them ...but I'd prefer a Java web application environment for i18n hands down), however the same basic ideas hold water using Velocity. At the time, application server misuse was in vogue and hundreds of thousands or even millions of dollars were being poured into "Enterprise Content Management" systems that coupled the CMS functions with those of publishing and request handling. Count that as millions of dollars squandered. There are still people struggling with the legacy of slow and stupid systems that can't be replaced because they spent too much money on it already (yea, what'd Forrest Gump say about stupid?). A few years later, when Aaron Swartz wrote about baking content he was insistent that he didn't care about performance, which is cool. The other benefits of baking that he mentions are perfectly valid. In fact, the publishing system at Salon.com distributes baked goods (HTML::Mason components generated with HTML::Mason components) to the web servers akin to Aaron's call to have something you can just do filesystem operations on. However, that's just the beginning. My maxim is that things that can scale independently should. The users of Bricolage, MovableType and other CMS and blog platforms that separate the management of editorial data, the publish cycle and content serving are enjoying that benefit right now.
java struts velocity i18n l10n CMS Bricolage MovableType mod_perl
( May 16 2005, 11:31:22 AM PDT ) Permalink
Tuesday April 19, 2005
Technorati as Tech Support: MacOS X update vs. Java This is a true story: an install of the recent MacOS X update bjorked the existing Java installation on a friend's powerbook. Just invoking "java -version" resulted in a lovely little "Segmentation fault." Thank you Cupertino!
A quick search on Technorati returned a pointer to the resolution from a post as the first result. The fix was to reinstall some security updates but the immediacy of the answer is what was really great.
All Hail The Real Time Web! ( Apr 19 2005, 03:01:57 PM PDT ) Permalink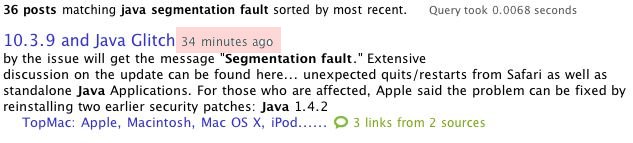
Tuesday April 12, 2005
Hello Berkeley DB This morning, I wanted to get familiar with the Berkeley DB "Java Edition" API (that's a mouthful, can't I just call it "sleepycat"?). I was in a carpool and I don't think the dude driving realized I was hacking-in-traffic. While I've happily used used DB_File in Perl for years-n-years, I haven't had time/opportunity to mess with the Java stuff from Sleepycat. However, at work we're cooking up a durable message buffer with an embedded servlet container, fun! As with poking into any new API, I like to start with Hello World.
Here's my Sleepycat Hello World
import com.sleepycat.je.Cursor;
import com.sleepycat.je.Database;
import com.sleepycat.je.DatabaseEntry;
import com.sleepycat.je.DatabaseConfig;
import com.sleepycat.je.DatabaseException;
import com.sleepycat.je.Environment;
import com.sleepycat.je.EnvironmentConfig;
import com.sleepycat.je.LockMode;
import com.sleepycat.je.OperationStatus;
import java.io.File;
public class HelloBdb {
public static void main(String[] args) throws Exception {
String key = args[0];
String value = args[1];
File dir = new File("db");
dir.mkdirs();
Environment env = new Environment(dir, new EnvironmentConfig());
Database database = env.openDatabase(null, "foobar", new DatabaseConfig());
database.put(null,
new DatabaseEntry(key.getBytes()), new DatabaseEntry(value.getBytes()));
DatabaseEntry foundKey = new DatabaseEntry();
DatabaseEntry foundData = new DatabaseEntry();
Cursor cursor = database.openCursor(null, null);
while (cursor.getNext(foundKey, foundData, LockMode.DEFAULT) ==
OperationStatus.SUCCESS) {
String keyString = new String(foundKey.getData());
String dataString = new String(foundData.getData());
System.out.println("Key | Data : " + keyString + " | " +
dataString + "");
}
cursor.close();
database.close();
env.close();
}
}
Of course, the real fun will be running this in a multi-threaded environment and the concurrency issues therein. With Hello World done, it's time to move on to see what else needs to be added to the cookbook.
( Apr 12 2005, 08:57:09 PM PDT ) Permalink
Monday January 10, 2005
Eclipse and iTunes Something's really goofy with my Powerbook!
If I'm listening to iTunes and then starting working in Eclipse, I get static popping and scratching in my ears. It hurts! It sucks! It just isn't right! Is this Apple's way of telling me they don't want me to develop code with Eclipse?
I'm marching over to MacWorld to protest!
( Jan 10 2005, 02:29:46 PM PST ) Permalink
Saturday January 08, 2005
Developer Contests Over the last few weeks I've been paying more attention to the API's that blog and taggregator services offer. I've also starting looking more into the API's that blog tools offer.
The Technorati Developer's Contest results are in. I was especially impressed with the visualization effort by Michael Dale'sTechnorati Touchgraph application. While it is a little rough around the edges in places (some of the implementation's PITA'ness is just AWT and crapplets being what they are), these kinds of graphical renderings of the Technorati cosmography are really great. Wondering now if anybody has tried something like this with Macromedia Flash, hmm....
If anybody is entering the Blojsom Developer Contest and wants help with the Technorati API, there's a Java client in the SDK and I'd be happy to lend assistance with it.
( Jan 08 2005, 12:04:12 PM PST ) Permalink
Sunday December 12, 2004
l10n development practices I've used Java's handy-dandy ResourceBundles to do some proof-of-concept localizations. But my past proofs were limited; they only used other European languages that utilized ISO-8859-1 characters. I don't recall having to do anything special with the property files in those cases.
Working on a recent Japanese localization project was an eye opening experience. It turns out the java.util.Properties expects ISO-8859-1 characters. I guess that's the downside of having a super-simple file format. I got the localized display boostrapped by using native2ascii to get the UTF-8 localization text rendered as escaped unicode. On a one-off basis, that's easy enough. But collaborative development always begs the tools question, how do folks typically manage this?
- Give the localization team instructions on how to use native2ascii on a command line basis?
- Put it in the build system with the native2ascii ant task?
- Use a light weight GUI tool like resourcebundleeditor (or a heavy weight GUI tool ...)?
What about input encoding? If there's an HTML form on a page and the input has multibyte characters in the query string (or POST data), are characters escaped to ISO-8859-1? My recollection was that HTTP headers must be ISO-8859-1.... but looking at the docs for PHP's mbstring and the encoding_translation parameter, it looks like server-side handling of the request needs to account for other character set encodings. Do browsers honor charset specification as a form attribute, like
<form action=... method=... accept-charset="UTF-8">(looks like Struts supports this) or is it presumed that the browser always escapes unicode? Or perhaps they simply URL encode the characters so it's a non-issue? On the server side the must the request handling do this
request.setCharacterEncoding("UTF-8");
String raw = request.getParameter("foo");
String clean = new String(raw.getBytes("ISO-8859-1"), "UTF-8");
or is it all supposed to transparently just work (obviating String cleansing) if request.setCharacterEncoding("UTF-8") is used?
...for all of the hand-waving in the docs for ResourceBundle, etc establishing a clear practice for input String handling in a webapp remains murky.
As far as sending responses, is it safe to always just send UTF-8 and include "charset=UTF-8" in the Content-type header? Is it standard practice to presume that the client will send a request header Accept-Charset (which indicates what an acceptable response is)? If they send it and UTF-8 isn't on the list, must the server go through a big String re-writing exercise to encode response to the browser's preference or is UTF-8 presumed to be implicitly acceptable at all times?
So many questions... I'm still digging for anwers.
( Dec 12 2004, 11:51:01 PM PST ) Permalink
Tuesday December 07, 2004
Runtime inseration of struts tiles in Velocity I've been impressed with TilesTool, it comes in the Velocity Tools package. It runs Velocity views through the struts MVC machine for processing reusable "subviews". However, there's no support for runtime insertion of components!
You can do this in tiles-defs.xml
<definition name=".dog" extends=".animal.layout">
<put name="body" value=".dog.display" />
<put name="head" value=".dog.head" />
</definition>
<definition name=".cosmos.head" extends=".head">
<put name="titleKey" value="dog.title" />
</definition>
<definition name=".dog.display"
controllerUrl="/dog.do"
path="/tile/dog.vm"
/>
and so forth. Declaritive tile composition works just fine. But what about programmatic composition at runtime?
With JSTL and struts, I can do this:
<c:forEach var="bit" items="${kibble}">
<tiles:insert page="/tile/bark.jsp">
<tiles:put name="bit" beanName="bit" />
</tiles:insert>
</c:forEach>
I would imagine that the Velocity equivalent would look like this:
<ol>
#foreach ($bit in $kibble)
$tiles.put("/tile/bark.vm", { "bit" : $bit })
#end
</ol>
but alas, it's not implemented by TilesTool. I can work around this by moving "bark.vm" to its own velocimacro but that it fugly as hell. I would prefer parameterized components.
( Dec 07 2004, 06:53:07 AM PST )
Permalink
Monday December 06, 2004
Servlet container forward from inside Velocity I ported some JSP UI code to Velocity, it's been fun learning the Velocity paradigm (being able to cleanly process template components outside the container rocks). One of the things in the JSP UI handled forwarding requests that bypassed the struts controller back through struts.
In JSP with struts tags, it looks like this (assume web.xml has "struts-logic" mapped):
<%@ taglib uri="struts-logic" prefix="logic" %> <logic:redirect forward="home"/>But what about Velocity? Well, it turns out that the VelocityViewServlet stuffs the basic servlet container things into the Velocity context, much like JSTL does in JSPville. Ergo, the $request object itself can be invoked like this:
$request.getRequestDispatcher("/home.do").forward($request,$response)
Seems kinda grotty to not be able to use struts symbolic name, but so far that's where my read of the Velocity docs has taken me. As I unpeel the onion, I may be inspired to subclass the VelocityViewServlet as a StrutsViewServlet... it seems like however you're invoking the rendering, you should be able to access, if present, other runtime services such as struts, spring, etc.
( Dec 06 2004, 10:05:35 AM PST )
Permalink
Sunday December 05, 2004
memcached in a service oriented functionality ecosystem Among my efforts over recent months have been those focused on decoupling. Technorati has a very high update rate as it taps the ping streams, fetches update contents, analyzes links and keyword indexes the substance of posts in the blogsphere. Such a system doesn't work well when components are closely coupled; the availability of the whole system is subject to the whim of the system's weakest links. Often, weaknesses are combinatorial; the weakness of the whole is greater than the weakness of the parts. That's what I'm focused on undoing. Fixing weaknesses in the components is important but decoupling them first is more so.
When folks say "service oriented architecture" it still cannotes monolithicism to me. An architecture implies a level of structure definition that sounds rigid; can you re-pour that foundation to adapt redrawn plans? Software development agility and loose coupling should reinforce each other. I prefer to think of architectures and ecosystems. A service oriented functionality ecosystem supplies application functionality as a suite of services. Supporting requirements (as opposed to the core business requirements) such security, logging, persistence, redundancy and caching are each handled independently; they in turn may be provisioned as services that higher level services rely on. This is part of the evolution under way at Technorati; some of the changes are evident in Dave's recent posts but some are just revisions that we're quietly rolling out.
Queues and distributed memory caches are natural elements of a such an environment. In the December issue of Linux Journal, Technorati's use of open source building blocks such as memcached is discussed by Doc Searls.
This is the game:
A memcached server (or a set of servers) can be accessed over the network to store things in a table kept in RAM. When storing things, you can specify a maximum age for the cache entry -- if you go back to fetch it and the elapsed time since it was stored exceeds that age, it gets treated as a cache miss.
Storing things in memcached with the timeout parameter and invalidating cache entries works as long as you have consistent mechanism for calculating the key. If internally you're managing "stories" and each one has an "id" attribute that is unique (a primary key), that's a good candidate to store them with. So for instance putting memcache inside a content management system (CMS) "content service" seems natural. In babytalk code:
public Story fetchStory(int storyId) {
Story story = memc.get(storyId);
if (story == null) // perhaps more rigorous validation of the fetched object
return story;
story = StoryDB.findById(storyId);
memc.put(storyId, story, AGE);
return(story);
}
If it's difficult to determine whether something is new or an update because it doesn't have an id and uniqueness is determined by some combination of attributes, then the lookup cycle can be helped by caching with composite keys. It gets a little more complicated:
public Story fetchStory(Map atts) {
// encapulate whatever attributes uniquely identify a thing
CacheKey key = new CacheKey(attrs);
Story story = memc.get(key);
if (story == null)
return story;
story = StoryDB.findByAttrs(attrs);
memc.put(key, story, AGE);
return(story);
}
We're in the process of evolving Technorati's infrastructure to one that is loosely coupled, redundant and robust. Our use of memcached is one of the enabling technologies of that evolution.
( Dec 05 2004, 09:22:23 AM PST ) Permalink
Sunday November 07, 2004
Tomcat's "Content-type" header parsing busted? One bit fun this week was trying to figure out why some XML output I was working was mangling characters. I thought I was doing all of the right things as far as handling the data goes. Well, I think I was but Tomcat 5.0.28 wasn't.
I poked around the Jakarta bug database and the only mention I could find that close was PR 31442, which described having this
<%@ page language="java" contentType="text/html; charset=UTF-8" %> <%@page pageEncoding="UTF-8"%>and saying that the text was coming back ISO8859-1 when the page is requested as a GET but not as a POST. Well, someone from the Jakarta project marked the bug INVALID glibly saying to ask on the user's mailing list and look at the Connector configuration because it's not a bug. WTF? Are you kidding?
Now I looked around in the Connector stanza's that come in the server.xml and see no mention of encoding configuration attributes. I've got a real simple test case.
<% response.setContentType("text/xml"); %>
triggers no funny encoding behavior, I get the data out as good old utf8 just as I wanted but if I did this
<% response.setContentType("text/xml; charset=UTF-8"); %>
....kablooey! Mangled encoding! That's just wrong. And if it's not wrong, I think it warrants a better answer than RTFM on the Connectors.
And the problem may not just be isolated to JSP handling. Judging from other reports that are turning up in Google's index pertaining to SetCharacterEncodingFilter, it's affecting the filter implemetation as well.
( Nov 07 2004, 02:46:58 AM PST ) Permalink
Wednesday October 20, 2004
Eclipse and Test Driven Development I've got some coding going on in Java, Perl, Python and PHP at the same (thus often self-query frequently: "Oh wait, which language am I working in for this bit?"). I've been using, at least partially, Test Driven Development with my current Java effort and It Is Good.
I've used Eclipse extensively in the past but since there was kinduva a long hiatus in Java development for me, it felt both novel and familiar to install it on my powerbook for the stuff I'm currently working on. I think that liberated feeling of knowing that That Thing Works So I Can Move On Now is referred to as being "Test Infected." Which, unlike the flu, is a good kind of infection. One of the things I've been trying to be more consistent about is writing tests prior to, or if not, concurrently with, application code. I strongly recommend reading Kent Beck's Test Driven Development (who BTW appears to have a work in progress about Eclipse), TDD is a quick read but more than any particular valuable agile techniques per se it offers a good outlook on how to think about what you're doing when you sit down to write code.
| Well, I was writing a few initial test cases for a class I was working on and noticed something new (to me anyway) when I clicked on an error that Eclipse flagged. The non-existence of the method in the called class was identified and Eclipse offered to stub it out on my behalf, this is a huge win as far as expressing an API in a test case and continuously filling in the functionality development "TODO" list. Everytime I want to add a new public method, I'll write a new test case and let Eclipse bootstrap the implementation. | |
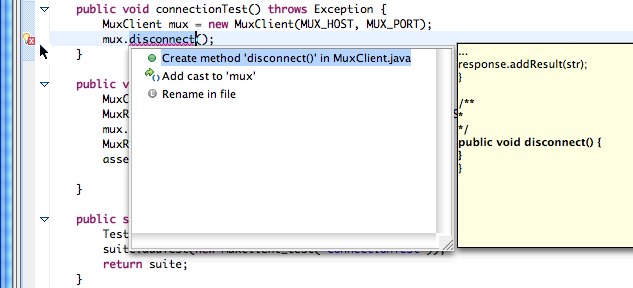
|
|
Read it:
|
Now if I could get that level of simplicity and automation working with Perl, Python or PHP, I'd be jammin'! Sure, there are testing frameworks for each of these but Eclipse really streamlines that whole TDD cycle. |
Forget about the flu shot hysteria, get "Test Infected"
( Oct 20 2004, 11:04:06 AM PDT ) Permalink


![[Valid RSS]](/images/valid-rss.png "Validate my RSS feed")