What's That Noise?! [Ian Kallen's Weblog]
 Friday March 19, 2010
Friday March 19, 2010
Programmatic Elastic MapReduce with boto
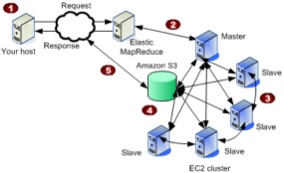 I'm working on some cloud-homed data analysis infrastructure. I may focus in the future on using the Cloudera distribution on EC2 but for now, I've been experimenting with Elastic MapReduce (EMR). I think the main advantages of using EMR are:
I'm working on some cloud-homed data analysis infrastructure. I may focus in the future on using the Cloudera distribution on EC2 but for now, I've been experimenting with Elastic MapReduce (EMR). I think the main advantages of using EMR are:
- Configuring the namenode, tasktracker and jobtracker is tedious, EMR relieves you of those duties
- Instance pool setup/teardown is tightly integrated
- Automated pool member replacement if an instance goes down
- Built in verbs like the "aggregate" reducer
- Programmatic and GUI operation
While there's a slick EMR client tool implemented in ruby, I've got a workflow of data coming in/out of S3, I'm otherwise working in Python (using an old friend boto) and so I'd prefer to keep my toolchain in that orbit. The last release of boto (v1.9b) doesn't support EMR but lo-and-behold it's in HEAD in the source tree. So if you check it out the Google Code svn repo as well as set your AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY environment variables, you can programmatically run the EMR wordcount sample like this:
from time import sleep
from datetime import datetime
from boto.emr.step import StreamingStep
from boto.emr.connection import EmrConnection
job_ts = datetime.now().strftime("%Y%m%d%H%M%S")
emr = EmrConnection()
wc_step = StreamingStep('wc text', \
's3://elasticmapreduce/samples/wordcount/wordSplitter.py', \
'aggregate', input='s3://elasticmapreduce/samples/wordcount/input', \
output='s3://wc-test-bucket/output/%s' % job_ts)
jf_id = emr.run_jobflow('wc jobflow', 's3n://emr-debug/%s' % job_ts, \
steps=[wc_step])
while True:
jf = emr.describe_jobflow(jf_id)
print "[%s] %s" % (datetime.now().strftime("%Y-%m-%d %T"), jf.state)
if jf.state == 'COMPLETED':
break
sleep(10)
Have fun hadooping!
hadoop boto python aws elasticmapreduce s3 ec2
( Mar 19 2010, 11:48:51 AM PDT ) Permalink
Thursday December 03, 2009
Scaling Rails with MySQL table partitioning
![]() Often the first step in scaling MySQL back-ended web applications is integrating a caching layer to reduce the frequency of expensive database queries. Another common pattern is to denormalize the data and index to optimize read response times. Denormalized data sets solve the problem to a point, when the indexes exceed reasonable RAM capacities (which is easy to do with high data volumes) these solutions degrade. A general pattern for real time web applications is the emphasis on recent data, so keeping the hot recent data separate from the colder, larger data set is fairly common. However, purging denormalized data records that have aged beyond usefulness can be expensive. Databases will typically lock records up, slow or block queries and fragment the on-disk data images. To make matters worse, MySQL will block queries while the data is de-fragmented.
Often the first step in scaling MySQL back-ended web applications is integrating a caching layer to reduce the frequency of expensive database queries. Another common pattern is to denormalize the data and index to optimize read response times. Denormalized data sets solve the problem to a point, when the indexes exceed reasonable RAM capacities (which is easy to do with high data volumes) these solutions degrade. A general pattern for real time web applications is the emphasis on recent data, so keeping the hot recent data separate from the colder, larger data set is fairly common. However, purging denormalized data records that have aged beyond usefulness can be expensive. Databases will typically lock records up, slow or block queries and fragment the on-disk data images. To make matters worse, MySQL will block queries while the data is de-fragmented.
MySQL 5.1 introduced table partitioning as a technique to cleanly prune data sets. Instead of purging old data and the service interruptions that a DELETE operation entails, you can break up the data into partitions and drop the old partitions as their usefulness expires. Furthermore, your query response times can benefit from knowing about how the partitions are organized; by qualifying your queries correctly you can limit which partitions get accessed.
But MySQL's partition has some limitations that may be of concern:
- The partitioning criteria must be an integer value. It's easy to express date information as integer values for the purposes of partitioning and in fact you can (albeit intrusively) partition with non integer values using triggers. But the underlying partitioning that MySQL implemented mandates integer criteria.
- All columns used in the partitioning expression for a partitioned table must be part of every unique key that the table may have. This will impact your design as to your use of primary keys and unique keys.
When we first looked at MySQL's table partitioning, this seemed like a deal breaker. The platform we've been working with was already on MySQL 5.1 but it was also a rails app. Rails has its own ORM semantics that uses integer primary keys. What we wanted were partitions like this:
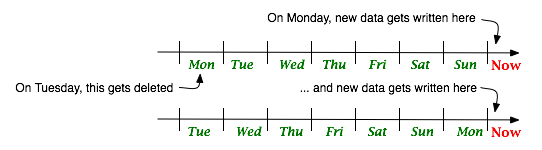
Here, data is segmented into daily buckets and as time advances, fresh buckets are created while old ones are discarded. Yes, with some social web applications, a week is the boundary of usefulness that's why there are only 8 buckets in this illustration. New data would be written to the "Now" partition, yesterday's data would be in yesterday's bucket and last Monday's data would be in the "Monday" bucket. I initially thought that the constraints on MySQL's partitioning criteria might get in the way; I really wanted the data partitioned by time but needed to partition by the primary keys (sequential integers) that rails used like this:
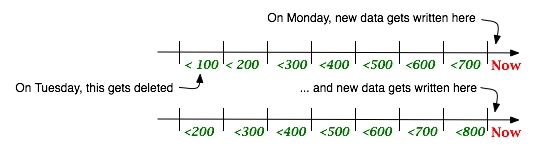
In this case, data is segmented by a ceiling on the values allowed in each bucket. The data with ID values less than 100 go in the first bucket, less than 200 in the second and so on.
Consider an example, suppose you had a table like this:
CREATE TABLE tweets ( id bigint(20) unsigned NOT NULL AUTO_INCREMENT, status_id bigint(20) unsigned NOT NULL, user_id int(11) NOT NULL, status varchar(140) NOT NULL, source varchar(24) NOT NULL, in_reply_to_status_id bigint(20) unsigned DEFAULT NULL, in_reply_to_user_id int(11) DEFAULT NULL, created_at datetime NOT NULL, PRIMARY KEY (id), KEY created_at (created_at), KEY user_id (user_id) );You might want to partition on the "created_at" time but that would require having the "created_at" field in the primary key, which doesn't make any sense. I worked around this by leveraging the common characteristic of rails' "created_at" timestamp and integer primary key "id" fields: they're both monotonically ascending. What I needed was to map ID ranges to time frames. Suppose we know, per the illustration above, that we're only going to have 100 tweets a day (yes, an inconsequential data volume that wouldn't require partitioning, but for illustrative purposes), we'd change my table like this:
ALTER TABLE tweets PARTITION BY RANGE (id) ( PARTITION tweets_0 VALUES LESS THAN (100), PARTITION tweets_1 VALUES LESS THAN (200), PARTITION tweets_2 VALUES LESS THAN (300), PARTITION tweets_3 VALUES LESS THAN (400), PARTITION tweets_4 VALUES LESS THAN (500), PARTITION tweets_5 VALUES LESS THAN (600), PARTITION tweets_6 VALUES LESS THAN (700), PARTITION tweets_maxvalue VALUES LESS THAN MAXVALUE );When the day advances, it's time create a new partition and drop the old one, so we do this:
ALTER TABLE tweets REORGANIZE PARTITION tweets_maxvalue into ( PARTITION tweets_7 VALUES LESS THAN (800), PARTITION tweets_maxvalue VALUES LESS THAN MAXVALUE ); ALTER TABLE tweets DROP PARTITION tweets_0;Programmatically determining what the new partition name should be (tweets_7) requires introspecting on the table itself. Fortunately, MySQL has metadata about tables and partitions in its "information_schema" database. We can query it like this
SELECT partition_ordinal_position AS seq, partition_name AS part_name, partition_description AS max_id FROM information_schema.partitions WHERE table_name='tweets' and table_schema='twitterdb' ORDER BY seq
So that's the essence of the table partition life-cycle. One issue here is that when we reorganize the partition, it completely rewrites it; it doesn't atomically rename "tweets_maxvalue" to "tweets_7" and allocate a new empty "tweets_maxvalue" (that would be nice). If the partition is populated with data, the rewrite is resource consumptive; the more data, the more so. The availability of a table that has a moderate throughput of data (let's say 1 million records daily, not 100) would suffer, locking the table for a long duration waiting for the rewrite is unacceptable for time sensitive applications. Given that issue, what we really want is to anticipate the ranges and reorganize the MAXVALUE partition in advance. When we allocate the new partition, we set an upper boundary on the ID values for but we need to make a prediction as to what the upper boundary will be. Fortunately, we put an index on created_at so we can introspect on the data to determine the recent ID consumption rate like this:
SELECT UNIX_TIMESTAMP(created_at),MAX(id) FROM tweets WHERE DATE(created_at)=DATE( now() - interval 1 day ); SELECT UNIX_TIMESTAMP(created_at),MAX(id) FROM tweets WHERE DATE(created_at)=DATE( now() - interval 2 day ); SELECT UNIX_TIMESTAMP(created_at),MAX(id) FROM tweets WHERE DATE(created_at)=DATE( now() - interval 3 day ); SELECT UNIX_TIMESTAMP(created_at),MAX(id) FROM tweets WHERE DATE(created_at)=DATE( now() - interval 4 day );The timestamps (epoch seconds) and ID deltas give us what we need to determine the ID consumption rate N; the new range to allocate is simply max(id) + N.
OK, so where's the rails? All of this so far has been transparent to rails. To take advantage of the partition access optimization opportunities mentioned above, it's useful to have application level knowledge of the time frame to ID range mappings. Let's say we just want recent tweets from a user M and we know that the partition boundary from a day ago is N, we can say
Tweet.find(:all, :conditions => ["user_id = M AND id > N"])This will perform better than the conventional (even if we created an index on user_id and created_at).
Tweet.find(:all, :conditions => ["user_id = M AND created_at > now() - interval 1 day"])Scoping the query to a partition in this way isn't unique to rails (or even to MySQL, with Oracle we can explicitly name the partitions we want a query to hit in SQL). Putting an id range qualifier in the WHERE clause of our SQL statements will work with any application environment. I chose to focus on rails here because of the integer primary keys that rails requires and the challenge that poses. To really integrate this into your rails app, you might create a model that has the partition metadata.
I hope this is helpful to others who are solving real time data challenges with MySQL (with or without rails), I didn't turn up much about how folks manage table partitions when I searched for it. There's an interesting article about using the MySQL scheduler and stored procedures to manage partitions but I found the complexity of developing, testing and deploying code inside MySQL more of a burden than I wanted to carry, so I opted to do it all in ruby and integrate it with the rails app. If readers have any better techniques for managing MySQL table partitions, please post about it!
Table partitioning handles a particular type of data management problem but it won't answer all of our high volume write capacity challenges. Scaling write capacity requires distributing the writes across independent indexes, sharding is the common technique for that. I'm currently investigating HBase, which transparently distributes writes to Hadoop data nodes, possibly in conjunction with an external index (solr or lucene), as an alternative to sharding MySQL. Hadoop is sufficiently scale free for very large workloads but real time data systems has not been its forte. Perhaps that will be a follow up post.
Further Reading:
Comments [1]
Sunday December 21, 2008
Python SVN Bindings, Trac and mod_python
![]() I have some code I want to noodle on outside of work. Since I'm on a holiday break, I'm doing a bit of that (yes, this is what I do for fun, so?). In the past, I had used my own private CVS server for those kinds of things but these days, I could just as well live without CVS. I decided to roll a subversion server into my Apache build (the latest Apache + other modules aren't in the yum repositories for my distro, so I roll my own). While I'm putting a subversion server up, why not trac, too? Heh, that's where things got stuck.
I have some code I want to noodle on outside of work. Since I'm on a holiday break, I'm doing a bit of that (yes, this is what I do for fun, so?). In the past, I had used my own private CVS server for those kinds of things but these days, I could just as well live without CVS. I decided to roll a subversion server into my Apache build (the latest Apache + other modules aren't in the yum repositories for my distro, so I roll my own). While I'm putting a subversion server up, why not trac, too? Heh, that's where things got stuck.
When I installed the subversion dependencies (specifically, neon), I just used vanilla build params. After installing subversion, I was surprised that Trac couldn't access it. It turns out that the litmus test was this:
$ python Python ... >>> from svn import core...it failed miserably. Various recompile efforts seemed to move the problem around. I saw a variety of the symptoms described in the Trac-Subversion integration docs troubleshooting section. The missing
gss_delete_sec_context symbol error was apparently the telltale critical one, it originated from neon having been compiled without SSL support. The neon compile config that led to success was
./configure --enable-shared --enable-static --with-ssl=opensslThen the real key was to completely start over with the subversion compile, not just the swig python bindings.
make clean ./configure \ --with-berkeley-db=/usr/local/BerkeleyDB.4.7 \ --prefix=/usr/local \ --with-apxs=/usr/local/httpd2.2.11/bin/apxs \ --with-apr=/usr/local/apr \ --with-apr-util=/usr/local/apr make make swig-py make check-swig-py make install make install-swig-py ldconfigOnly then did the litmus test above pass. One of the things about this setup that is kind of a nuisance is that the python bindings didn't get installed into
site-packages, therefore mod_python was quite unhappy. Also, trac seemed to want to put its eggs in the root directory. So the Apache server's envvars script has these variables exported to work around those issues
PYTHONPATH=/usr/local/lib/svn-python LD_LIBRARY_PATH=/usr/local/lib/svn-python/libsvn PYTHON_EGG_CACHE=/data1/egg_cacheThe result (including the requisite
httpd.conf tweaks) is a working subversion 1.54 and trac 0.11 setup. It was more fiddling for the evening than I'd hoped for and I'm not sure my foibles and remedies were optimal (clearly, I missed an RTFM somewhere) but I hope this resolution helps at least one reader.
Happy Hannukah and winter solstice!
apache mod_python trac neon subversion swig python
( Dec 21 2008, 02:55:24 PM PST ) Permalink
Monday December 08, 2008
Good Bye, Perl
![]() The other day, I was patching some Perl code. There I was, in the zone, code streaming off of my finger tips. But wait, I was writing Python in the middle of a Perl subroutine. Um. I found the bare word and missing semi-colon errors invoking
The other day, I was patching some Perl code. There I was, in the zone, code streaming off of my finger tips. But wait, I was writing Python in the middle of a Perl subroutine. Um. I found the bare word and missing semi-colon errors invoking perl -cw dingleberry.pl amusing. How did that happen?
Truth is, I find myself rarely using Perl anymore. I spent years building applications with Perl. Having made extensive use of mod_perl APIs and various CPAN modules, studied the Talmudic wisdom of Damian Conway, struggled with the double-edged sword of TMTOWTDI and rolled my eyes at the Perl haters for their failure to appreciate the strange poetry that is Perl it'd seem like a safe bet that Perl would remain on my top shelf. A lot of the complaints of Perl haters seem superficial ("ewe, all of those punctuation characters", shaddup). Yet, Perl has been long in the tooth, for a long time. I recall 5 years ago thinking that Perl 6 wasn't too far away (after all, O'Reilly published Perl 6 Essentials in June 2003). I'm sorry, my dear Perl friends, insistence that Perl is Alive rings hollow, now.
I still find it heartening to hear of people doing cool things with Perl. David McLaughlin's uplifting How I learnt to love Perl, waxing on about Moose and other "modern" Perl frameworks (but come on dude, everyone knows that PHP, sucks, heh). Brad Fitzpatrick released Perl for Google App Engine today. But Perl, I'm sorry. It's just too little, too late.
I'm just weary of the difficulties achieving team adherence to disciplined coding practices (or even appreciate why they're especially necessary in the TMTOWTDI world of Perl). The reliance on Wizardry is high with Perl; the path from novice to master requires grasping a wide range of arcana. Is it too much to ask for less magic in favor of easier developer ramp up? Perl's flexibility and expressiveness, it's high virtues, also comprises the generous reel of rope that programmers routinely hang themselves with. On top of idiomatic obscurities are the traps people fall into with dynamic typing and errors that only make themselves evident at runtime. Good testing practices are usually the anecdote to the woes of dynamic typing and and yet writing a good test harness for a Perl project is often a lot of work compared to the amount of work required to write the application code.
I well understand the security that programmers feel using static typing but I'm not saying the static typing is the cure to any ills. The compiler is the most basic test that your code can be understood and it gives your IDE a lotta help. That's great but static typing is also an anchor dragging on your time. From what I can tell, Java is the new C/C++ and Jython, JRuby. Groovy and friends (Scala, Clojure, etc) are the ways that people program the JVM with higher productivity. I'm not saying fornever to Perl (that's a long time). But I am saying Hasta La Vista, for now. I've been quite productive lately with Python (I know Perl friends, heresy!) and plan on pushing ahead with that, as well as with Java and other JVM languages. And where necessary, using Thrift to enable the pieces to work together. Python is certainly not perfect, it's quirks are many, too. But I've seen recent success with collaborative software development with Python that would have been difficult to accomplish with Perl. I'm not trying to stoke any language war at all, I'm just reflecting on how I've drifted from Perl. Amongst people I know and things I've read elsewhere, I'm not the only one. Don't fret, Perl, I'm sure I'll see you around.
( Dec 08 2008, 12:01:24 AM PST ) PermalinkComments [7]
Saturday December 06, 2008
MySQL vs. PostgreSQL (again)
![]()
![]() If Kevin Burton wanted to draw attention to MySQL's inattention to scalability concerns, it looks like he's succeeded (126 comments on Reddit in the last day and climbing). I totally understand why he feels that the MySQL folks need to be provoked into action. I'll confess to having serious "MySQL fatigue" after years of struggling with InnoDB quirks (we use MySQL extensively at Technorati), stupid query plans and difficult to predict performance inflection points (there's a calculus behind table row count, row width, number of indices, update rate and query rate -- but AFAIK nobody has a reliable formula to predict response times against those variables). Frankly, I was really surprised when Sun acquired MySQL (for such a hefty sum, too), I was expecting them to build up a PostgreSQL-based platform by rolling up acquisitions of Greenplum and Truviso.
If Kevin Burton wanted to draw attention to MySQL's inattention to scalability concerns, it looks like he's succeeded (126 comments on Reddit in the last day and climbing). I totally understand why he feels that the MySQL folks need to be provoked into action. I'll confess to having serious "MySQL fatigue" after years of struggling with InnoDB quirks (we use MySQL extensively at Technorati), stupid query plans and difficult to predict performance inflection points (there's a calculus behind table row count, row width, number of indices, update rate and query rate -- but AFAIK nobody has a reliable formula to predict response times against those variables). Frankly, I was really surprised when Sun acquired MySQL (for such a hefty sum, too), I was expecting them to build up a PostgreSQL-based platform by rolling up acquisitions of Greenplum and Truviso.
Kevin is totally correct that to find solid innovation with MySQL, don't look to the MySQL corporation. Instead, the consultants and third party shops specializing in MySQL are where the action's at (Palomino DB, Percona, Drizzle, etc). It's kinda sad, both Sun and MySQL have at various times been home to hot-beds of innovation. Sun has great people groundbreaking with cloud computing, impressive CPU performance per watt improvements and the Java ecosystem. But as far as MySQL goes, look to the outside practitioners.
Kevin's post update cites the pluggable back-ends that MySQL supports as a feature but I'm not so sure. I don't have any evidence of this but my intuition is that it's exactly this feature that makes the overall stability and performance such a crap-shoot (or sometimes, just outright crap). I'm working on a personal project that uses PostGIS (PostgreSQL + GIS), nothing is live yet so I haven't had to scale it. But I have a good deal of confidence in the platform. Skype and Pandora look like good case studies. The PostgreSQL people have been focused on MVCC concurrency, procedure languages, UDFs and data integrity semantics for years. In those realms, the MySQL people are Johnny-come-slowlies (and buggily). On the other hand, if you want the append-only characteristics of logging to a database, MyISAM and merge tables have performance properties that PostgreSQL just can't match.
Maybe David Duffield will look beyond enterprise app services and acquire, roll-up and market the PostgreSQL platforms that Sun didn't. Combining big data and event data with Greenplum and Truviso as a way to blow some smoke in Larry Ellison's eye, that would be funny (and smart).
postgresql mysql greenplum truviso sun workday postgis
( Dec 06 2008, 12:08:20 PM PST ) Permalink
Friday October 26, 2007
memcached hacks
 I needed to clear a cache entry from a memcached cluster of 5 instances. Since I didn't know which one the client had put it in, I concocted a command line cache entry purger. netcat AKA nc(1) is my friend.
I needed to clear a cache entry from a memcached cluster of 5 instances. Since I didn't know which one the client had put it in, I concocted a command line cache entry purger. netcat AKA nc(1) is my friend.
Let's say the cache key is "shard:7517" and the memcached instances are running on hosts ghcache01, ghcache02, ghcache03, ghcache04 and ghcache05 on port 11111 the incantation to spray them all with a delete command is
$ for i in 1 2 3 4 5 > do echo $i && echo -e "delete shard:7517\r\nquit\r\n" | nc -i1 ghcache0$i 11111 > doneand the output looks like
1 NOT_FOUND 2 DELETED 3 NOT_FOUND 4 NOT_FOUND 5 NOT_FOUNDwhich indicates that the memcached instance on ghcache02 had the key and deleted it (note the memcached protocol response: DELETED), the rest didn't have it and returned NOT_FOUND.
For more information on the memcached protocol, see the docs under source control.
( Oct 26 2007, 12:29:37 PM PDT ) Permalink
Sunday October 14, 2007
Benchmarks Smenchmarks
![]() I've been hearing about folks using the LightSpeed web server instead of Apache for its supposed performance gains and ease of use. OK, so maybe if you're not familiar with the subtleties and madness of Apache, it can seem complicated. But the performance issues are often red herrings. Granted, it's been a few years since I've done any web server benchmarking but from my previous experience with these things, the details really matter for the outcomes and in the real world, the outcomes themselves matter very little.
I've been hearing about folks using the LightSpeed web server instead of Apache for its supposed performance gains and ease of use. OK, so maybe if you're not familiar with the subtleties and madness of Apache, it can seem complicated. But the performance issues are often red herrings. Granted, it's been a few years since I've done any web server benchmarking but from my previous experience with these things, the details really matter for the outcomes and in the real world, the outcomes themselves matter very little.
The benchmark results published on the LightSpeed Technologies web site raised a flag for me right away: their comparison to Apache 2.0 was with the pre-forked MPM instead of the worker MPM. Is it any wonder that the results are pretty close to those for Apache 1.3? Either they had no idea what they were doing when they performed this benchmark or they knew exactly what they were doing and were burying the superior scalability of the worker MPM. Pitting a threaded or event driven process model against a forked one is just stupid. However, the evidence leans more towards willful sloppiness or fraud than ignorance. For instance, they claim to have raised the concurrency on Apache above 10k connections ... but they link to an httpd.conf that has MaxClients set to 150. RTFM, that can't happen.
Why don't these things matter in the real world? In benchmark world, there aren't varying client latencies (slow WAN links, etc), varying database response times (for instance MySQL's response times are very spikey), the vagueries of load balancers ebbing and flowing the load and logging configurations aren't set up for log data management. In the real world, application design and these various externalities are the culprits in application performance, not CPU bottlenecks in the web server runtime. The PHP interpreter itself is likely not your bottleneck either. If you're writing crap-assed code that performs unnecessary loops or superfluous database calls, it's going to run like crap no matter what web server is driving it (I've had to pick through a lot of error-ridden PHP code in my day). With Apache's support for sendfile() static file serving and all of the flexibility you get from mod_proxy, mod_rewrite and the rest of the toolkit, I don't understand the appeal of products like LightSpeed's.
( Oct 14 2007, 11:43:08 PM PDT ) Permalink
Wednesday May 16, 2007
PostgreSQL Quirk: invalid domains
![]() I've had my fill of MySQL's quirks, so I thought I'd plumb for PostgreSQL's. So many things that MySQL is fast and loose about, PostgreSQL is strict and correct. However, I was fiddling around with PostgreSQL's equivalent to MySQL's
I've had my fill of MySQL's quirks, so I thought I'd plumb for PostgreSQL's. So many things that MySQL is fast and loose about, PostgreSQL is strict and correct. However, I was fiddling around with PostgreSQL's equivalent to MySQL's enum and found what I would expect a strict RDBMS to be strict about... not so strict.
PostgreSQL does not have enum but there are a few different ways you can define your own data types and constraints and therefore prescribe your on constrained data type. This table definition will confine the values in 'selected' to 5 characters with the only options available being 'YES', 'NO' or 'MAYBE':
ikallen=# create table decision ( selected varchar(5) check (selected in ('YES','NO','MAYBE')) );
CREATE TABLE
ikallen=# insert into decision values ('DUH');
ERROR: new row for relation "decision" violates check constraint "decision_selected_check"
ikallen=# insert into decision values ('CLUELESS');
ERROR: value too long for type character varying(5)
ikallen=# insert into decision values ('MAYBE');
INSERT 0 1
I don't want to hear any whining about how diff-fi-cult constrained types are. Welcome to the NBA, where RDBMS' throw elbows. The flexibility you get from loosely constrained types will come back to bite you on your next programming lapse.
So what's wrong with this:
ikallen=# create table indecision ( selected varchar(5) check (selected in ('YES','NO','MAYBE SO')) );
CREATE TABLE
ikallen=# insert into indecision values ('MAYBE');ERROR: new row for relation "indecision" violates check constraint "indecision_selected_check"
ikallen=# insert into indecision values ('MAYBE SO');
ERROR: value too long for type character varying(5)
ikallen=#
'MAYBE SO' is in my list of allowed values but violates the width constraint. Should this have ever been allowed? Shouldn't PostgreSQL have complained vigorously when a column was defined with varchar(5) check (selected in ('YES','NO','MAYBE SO'))? Yes? No? Maybe?
Well, I think so.
One of the cool things about PostgreSQL is the ability to define a constrained type and use it in your table definitions:
ikallen=# create domain ynm varchar(5) check (value in ('YES','NO','MAYBE'));
CREATE DOMAIN
ikallen=# create table coolness ( choices ynm );
CREATE TABLE
ikallen=# insert into coolness values ('nope');
ERROR: value for domain ynm violates check constraint "ynm_check"
ikallen=# insert into coolness values ('YES');
INSERT 0 1
Coolness!
Contrast with MySQL's retarded handling of what you'd expect to be a constraint violation:
mysql> create table decision ( choice enum('YES','NO','MAYBE') );
Query OK, 0 rows affected (0.01 sec)
mysql> insert into decision values ('ouch');
Query OK, 1 row affected, 1 warning (0.03 sec)
mysql> select * from decision;
+--------+
| choice |
+--------+
| |
+--------+
1 row in set (0.00 sec)
mysql> select length(choice) from decision;
+----------------+
| length(choice) |
+----------------+
| 0 |
+----------------+
1 row in set (0.07 sec)
mysql> insert into decision values ('MAYBE');
Query OK, 1 row affected (0.00 sec)
mysql> select * from decision;
+--------+
| choice |
+--------+
| |
| MAYBE |
+--------+
2 rows in set (0.00 sec)
mysql> select length(choice) from decision;
+----------------+
| length(choice) |
+----------------+
| 0 |
| 5 |
+----------------+
2 rows in set (0.00 sec)
Ouch, indeed. Wudz up wit dat?
There are a few things that MySQL is really good for but if you want a SQL implementation does what you expect for data integrity, you should probably be looking elsewhere.
postgresql mysql rdbms databases
( May 16 2007, 07:33:00 PM PDT ) Permalink
Wednesday April 25, 2007
Intel Migration Pain With Perl
![]() There's a bunch of code that I haven't had to work on in months. Some of it predates my migration from PPC Powerbook to the Intel based MacBook Pro. Now that I'm dusting this stuff off, I'm running to binary incompatibilities that are messin' with my head. My recompiled my Apache 1.3/mod_perl installation just fine but doing a CVS up on the code I need to work on and updating the installation, there's a new CPAN dependency. No problem, use the CPAN shell. Oh, Class::Std::Utils depends on version.pm and it's ... the wrong architecture. Re-install version.pm. Next, XMLRPC::Lite is unhappy 'cause it depends on XML::Parser::Expat and it's ... the wrong architecture.
There's a bunch of code that I haven't had to work on in months. Some of it predates my migration from PPC Powerbook to the Intel based MacBook Pro. Now that I'm dusting this stuff off, I'm running to binary incompatibilities that are messin' with my head. My recompiled my Apache 1.3/mod_perl installation just fine but doing a CVS up on the code I need to work on and updating the installation, there's a new CPAN dependency. No problem, use the CPAN shell. Oh, Class::Std::Utils depends on version.pm and it's ... the wrong architecture. Re-install version.pm. Next, XMLRPC::Lite is unhappy 'cause it depends on XML::Parser::Expat and it's ... the wrong architecture.
Aaaaugh!
The typical error looks like
mach-o, but wrong architecture at /System/Library/Perl/5.8.6/darwin-thread-multi-2level/DynaLoader.pmI just said "screw it" and typed "cpan -r" ... which looks to be the moral equivalent of "make world" from back in my FreeBSD days. Everything that has an XS interface just needs to be recompiled.
Compiling... compiling... compiling. I guess that'll give me time to write a blog post about it. OK, that's done, seems to have fixed things: back to work.
perl mac apple macosx intel expat cpan macbook pro powerbook
( Apr 25 2007, 05:19:37 PM PDT ) Permalink
Monday April 23, 2007
Simple is as simple ... dohs!
![]() I was working on an Evil Plan (tm) to serialize python feedparser results with simplejson.
I was working on an Evil Plan (tm) to serialize python feedparser results with simplejson.
parsedFeed = feedparser.parse(feedUrl) print simplejson.dumps(parsedFeed)Unfortunately, I'm hitting this:
TypeError: (2007, 4, 23, 16, 2, 7, 0, 113, 0) is not JSON serializableI'm suspecting there's a dictionary in there that has a tuple as key and that's not allowed in JSON-land. So much for simple! Looks like I'll be writing a custom serializer fror this. I was just trying to write a proof-of-concept demo; what I've proven is that just 'cause "simple" is in the name, doesn't mean I'll be able to do everything I want with it very simply.
I've had a long day. A good night's sleep and fresh eyes on it tomorrow will probably get this done but if yer reading this tonight and you happen to have something crafty up your sleeve for extending simplejson for things like this, let me know!
( Apr 23 2007, 10:50:21 PM PDT ) Permalink
Sunday April 22, 2007
Linux Virtual Memory versus Apache
![]() I ran into a very peculiar case of an Apache 2.0.x installation with the worker MPM completely failing to spawn it's configured thread pool. The hardware and kernel versions weren't significantly different from other systems running Apache with the same configuration. Here are the worker MPM params in use:
I ran into a very peculiar case of an Apache 2.0.x installation with the worker MPM completely failing to spawn it's configured thread pool. The hardware and kernel versions weren't significantly different from other systems running Apache with the same configuration. Here are the worker MPM params in use:
ServerLimit 40 StartServers 20 MaxClients 2000 MinSpareThreads 50 MaxSpareThreads 2000 ThreadsPerChild 50 MaxRequestsPerChild 0But on this installation, same version of Apache and RedHat Enterprise Linux 4 like rest, every time httpd started it would cap the number threads spawned and leave these remarks in the error log:
[Fri Apr 20 22:54:24 2007] [alert] (12)Cannot allocate memory: apr_thread_create: unable to create worker thread
It turns out that a virtual memory parameter had been adjusted, vm.overcommit_memory had been set to 2 instead of 0. Here's the explanation of the parameters I found:
overcommit_memory is a value which sets the general kernel policy toward granting memory allocations. If the value is 0, then the kernel checks to determine if there is enough memory free to grant a memory request to a malloc call from an application. If there is enough memory, then the request is granted. Otherwise, it is denied and an error code is returned to the application. If the setting in this file is 1, the kernel allows all memory allocations, regardless of the current memory allocation state. If the value is set to 2, then the kernel grants allocations above the amount of physical RAM and swap in the system as defined by the overcommit_ratio value. Enabling this feature can be somewhat helpful in environments which allocate large amounts of memory expecting worst case scenarios but do not use it all.The vm.overcommit_ratio value is set to 50 on all of our systems but rather than fiddling with that, setting vm.overcommit_memory to 0 had the intended effect; Apache started right up and readily stood-up to load testing.
From Understanding Virtual Memory
So, if you're seeing these kind of evil messages in your Apache error log, use sysctl and check out the vm parameters. I haven't dug further into why the worker MPM was conflicting with this memory allocation config; next time I run into Aaron, I'm sure he'll have an explanation in his back pocket.
apache linux worker mpm threads redhat linux vm virtual memory
( Apr 22 2007, 08:19:57 PM PDT ) Permalink
Monday April 16, 2007
Character Encoding Foibles in Python
![]() I was recently stymied by an encoding error (the exception thrown was kicked off by UnicodeError) on a web page that was detected as utf-8, the W3 Validator said it was utf-8 but in all my efforts to get a parsing classes derived from python's SGMLParser, it consistently bombed out. I tried chardet:
I was recently stymied by an encoding error (the exception thrown was kicked off by UnicodeError) on a web page that was detected as utf-8, the W3 Validator said it was utf-8 but in all my efforts to get a parsing classes derived from python's SGMLParser, it consistently bombed out. I tried chardet:
>>> import chardet
>>> import urllib
>>> urlread = lambda url: urllib.urlopen(url).read()
>>> chardet.detect(urlread(theurl))
{'confidence': 0.98999999999999999, 'encoding': 'utf-8'}
...and yet the parser insisted that it had hit the "'ascii' codec can't decode byte XXXX in position YYYY: ordinal not in range(128)" error. WTF?!
On a hunch, I decided to try forcing it to be treated as utf-16 and then coercing it back to utf-8, like this
parser.feed(pagedata.encode("utf-16", "replace").encode("utf-8"))
That worked!
I hate it when I follow an intuited hunch, it pans out and but I don't have any explanation as to why. I just don't know the details of python's character encoding behaviors to debug this further, most of my work is in those Curly Bracket languages :)
If any python experts are having any "OMG don't do that, here's why..." reactions, please let me know!
python utf8 character sets character encoding chardet sgmlparser
( Apr 16 2007, 11:28:31 AM PDT ) Permalink
Monday August 28, 2006
Memcached In MySQL The MySQL query cache has rarely been of much use to me since it's a pretty much just an optimization for read-heavy data. Furthermore, if you have a pool of query hosts (e.g. you're using MySQL replication to provide a pool of slaves to select from), each with its own query cache in a local silo, there's no "network effect" of benefitting from a shared cache. MySQL's heap tables are a neat trick for keeping tabular data in RAM but they don't work well for large data sets and suffer from the same siloization as the query cache. The standard solution for this case is to use memcached as an object cache. The elevator pitch for memcached: it's a thin distributed hash table in local RAM stores accessible by a very lightweight network protocol and bereft of the featuritus that might make it slow; response times for reads ands writes to memcached data stores typical clock in at single digits of milliseconds.
RDBMS-based caches are often a glorified hash table; a primary key'd column and value column. Using an RDBMS as a cache works but it's kinda overkill; you're not using the "R" in RDBMS. Anyway, transacting with a disk based storage engine that's concerned with ACID bookkeeping isn't an efficient cache. MySQL has the peculiar property of supporting pluggable storage backends. MyISAM, InnoDB and HEAP backends are the most commonly used ones. Today, Brian Aker (of Slashdot and MySQL AB fame) announced his first cut release of his memcache_engine backend.
Here's Brian's example usage:
mysql> INSTALL PLUGIN memcache SONAME 'libmemcache_engine.so' ; create table foo1 (k varchar(128) NOT NULL, val blob, primary key(k)) ENGINE=memcache CONNECTION='localhost:6666';
mysql> insert into foo1 VALUES ("mine", "This is my dog");
Query OK, 1 row affected (0.01 sec)
mysql> select * from foo1 WHERE k="mine";
+------+----------------+
| k | val |
+------+----------------+
| mine | This is my dog |
+------+----------------+
1 row in set (0.01 sec)
mysql> delete from foo1 WHERE k="mine";
Query OK, 1 row affected (0.00 sec)
mysql> select * from foo1 WHERE k="mine";
Empty set (0.01 sec)
Brian's release is labelled a pre-alpha, some limitations apply, your milage my vary, prices do not include taxes, customs or agriculture inspection fees.
- What works
-
- SELECT, UPDATE, DELETE, INSERT
- INSERT into foo SELECT ...
- What doesn't work
-
- Probably ORDER BY operations
- REPLACE (I think)
- IN ()
- NULL
- multiple memcache servers (this would be cake though to add)
- table namespace, right now it treats the entire server as one big namespace
Sunday August 27, 2006
Stupid Object Tricks When I wrote about OSCON last month, I mentioned Perrin Harkins's session on Low Maintenance Perl, which was a nice review of the do's and don'ts of programming with Perl, I really didn't dig into the substance of his session. Citing Andy Hunt (from Practices of an Agile Developer):
When developing code you should always choose readability over convenience. Code will be read many, many more times than it is written. (see book site)Perrin enumerated a lot of the basic rules of engagement for coding Perl that doesn't suck. Some of the do's and don'ts highlights:
- Do's
-
- use strict
- use warnings
- use source control
- test early and often, specifically recommending Test::Class and smolder
- follow conventions when you can
- Don'ts
-
- don't use formats (use sprintf!)
- don't mess with UNIVERSAL (it's the space-time continuum of Perl objects)
- don't define objects that aren't hashes ('cept inside outs)
- don't rebless an existing object into a different package (if you describe that as polymorphism in a job interview, expect to be shown the door real quick)
package Foo;
sub new {
my $class = shift;
my $data = shift || {};
return bless $data, $class;
}
package main;
my $foo = Foo->new;
print ref $foo, "\n";
bless $foo, 'Bar';
print ref $foo, "\n";
For the non-Perl readers, create an instance of Foo ($foo), then change it to an instance of Bar, printing out the class names as you go. The output is:
Foo BarAnyone caught doing this will certainly come back as a two headed cyclops in the next life.
I've been trying to increase my python craftiness lately. I first used python about 10 years ago (1996) at GameSpot, we used it for our homebrewed ad rotation system. I fiddled with python some more at Salon as part of the maintenance of our ultraseek search system. But basically, python has always looked weird to me and I've avoided doing anything substantial with it. Well, my interest in it is renewed because there is a substantial amount of legacy code that I'm presently eyeballing and, anyway, I'm very intrigued by JVM scripting languages such as Jython (and JRuby). I'm looking for a best-of-both-worlds environment, things-are-what-you-expect static typing and compile time checking on the one hand and rapid development on the other. I was really astonished to learn that chameleon class assignment like Perl's is supported by Python. Python is strongly typed in that you have to explicitly cast and coerce to change types (very unlike Perl's squishy contextual operators which does a lot of implicit magic). But Python is also dynamically typed, an object's type is a runtime assignment. This is gross:
class Foo:
def print_type(self):
print self.__class__
class Bar:
def print_type(self):
print self.__class__
if __name__ == "__main__":
foo = Foo();
foo.print_type();
foo.__class__ = Bar
foo.print_type();
In English, create an instance of Foo (foo), then change it to an instance of Bar, printing out the class names as you go. The output is:
__main__.Foo __main__.Bar(Python prefices the class name with the current namespace, __main__) Anyone caught doing this will certainly come back as a reptilian jackalope in the next life.
Of course, Java doesn't tolerate any of these shenanigans. Compile time complaints of "what, are you crazy?!" would surely come hither from javac. There's no setClass(Class):void method in java.lang.Object, thank goodness, even though there is getClass():Class. One of the key characteristics of a language's usefulness for agile development has to be its minimalization of astonishing results, quirky idioms and here-have-some-more-rope-to-hang-yourself behaviors. If you can't read your own code from last month without puzzling over it, how the hell are you going to refactor it quickly and easily next month? Will your collaborators have an easier time with it? Perl has rightly acquired the reputation of a "write once, puzzle forevermore" language. I haven't dug into whether Ruby permits runtime object type changing (that would be really disappointing). I'll dig into that next, clearly the rails developers emphasis on convention and configuration over code is aimed at reducing the surprises that coders can cook up. But that doesn't necessarily carry back to Ruby itself.
python perl ruby java code agile programming jython jruby oscon oscon06
( Aug 27 2006, 08:51:11 AM PDT ) Permalink
Tuesday February 14, 2006
Oracle's "Resistance is Futile" Message to MySQL? Five months after scooping up InnoDB, a major technology provider to MySQL AB, it looks like Larry is borging them further. MySQL users who depend on InnoDB for transaction support were no doubt shaken by that announcement but, since MySQL has other backends, there's at least some assurance there that transactional capabilities won't be completely chopped into little pieces, wrapped in a carpet and tossed into a Redwood Shores swamp; there's always other vendors, like Sleepycat and their BerkeleyDB product, right?
Bwah hah hah! Larry's got a Bloody Valentine for you now! Seems as though an undisclosed sum has been passed and another one bites the dust. This article suggests that Oracle's also set its sites on JBoss and Zend (the latter of which currently has BD2 support front and center on their home page). Mark Fluery and Larry Ellison ... that has a ring to it!
I think it's time to solve the PostgreSQL database replication problem (no, Slony is not a good answer) for once and for all, lest Larry's bloodthirst vaporize MySQL.
borg oracle mysql sleepycat innodb jboss zend
( Feb 14 2006, 03:55:40 PM PST ) Permalink


![[Valid RSS]](/images/valid-rss.png "Validate my RSS feed")