What's That Noise?! [Ian Kallen's Weblog]
 Tuesday March 31, 2009
Tuesday March 31, 2009
Cloning VMware Machines
![]() I bought a copy of VMware Fusion on special from Smith Micro (icing on the cake: they had a 40% off special that week) specifically so I could simulate a network of machines on my local MacBook Pro. While I've heard good things about Virtual Box, one of the other key capabilities I was looking for from MacIntosh virtualization software was the ability convert an existing Windows installation to a virtual machine. VMware reportedly has the best tools for that kind of thing. I have an aging Dell with an old XP that I'd like to preserve when I finally decide to get rid of the hardware; when it's time to Macify, I'll be good to go.
I bought a copy of VMware Fusion on special from Smith Micro (icing on the cake: they had a 40% off special that week) specifically so I could simulate a network of machines on my local MacBook Pro. While I've heard good things about Virtual Box, one of the other key capabilities I was looking for from MacIntosh virtualization software was the ability convert an existing Windows installation to a virtual machine. VMware reportedly has the best tools for that kind of thing. I have an aging Dell with an old XP that I'd like to preserve when I finally decide to get rid of the hardware; when it's time to Macify, I'll be good to go.
I started building my virtual network very simply, by creating a CentOS VM. Once I had my first VM running, I figured I could just grow the network from there; I was expecting to find a "clone" item in the Fusion menus but alas, no joy. So, it's time to hack. Looking around at the artifacts that Fusion created, a bunch of files in a directory named for the VM, I started off by copying the directory, the files it contained that had the virtual machine name as components of the file name and edited the metadata files ({vm name}.vmdk/.vmx/.vmxf). Telling Fusion to launch that machine, it prompted if this was a copy or a moved VM - I told it that it was copied and the launch continued. Both launched VM's could ping each other so voila: my virtual network came into existence.
I've since found another procedure to create "linked clones" in VMware Fusion. It looks like this will be really useful for my next scenario of having two different flavors of VM's running on my virtual network. The setup I want to get to is one where I can have "manager" host (to run provisioning, monitoring and other management applications) and cookie-cutter "worker" hosts (webservers, databases, etc). Ultimately, this setup will help me tool up for cloud platform operations; I have more Evil Plans there.
So all of this has me wondering: why doesn't VMware support this natively? Where's that menu option I was looking for? Is there an alternative to this hackery that I just overlooked?
vmware virtualization centos vmware fusion vm cloning
( Mar 31 2009, 09:12:22 AM PDT ) PermalinkComments [2]
Thursday March 12, 2009
Going to Metallica's Rock and Roll Hall of Fame Induction
 Those 25 things you should know about me memes circulating rarely interest me (honestly, I don't care that you have a collection of rare El Salvadoran currency). However, one thing that my friends know but regular readers may not is that I have a fairly eclectic background. Did you know that I used to hang around the art department's hot glass studio in college to blow glass? Did you know that I learned to program in Pascal when I was in college and hated it? Yea, yea, I don't care much anymore either. But anyway, back in the 80's I was friends with this Danish dude from LA who shared my interest in the underground heavy metal scene that was burgeoning, particularly in Britain ("New Wave of British Heavy Metal" AKA NWOBHM) and Europe. We used to trade records and demos (the first Def Leppard 3 song EP on 9" vinyl, I was tired of it so I traded him for a bunch of Tygers of Pan Tang and other crap I didn't own already). I think he, like myself, used to pick up copies of Melody Maker and Sounds at the local record store to read about what was going on overseas. Eventually, Kerrang! came out providing fuller coverage of the metal scene, complete with glossy pictures. But in the meantime back in San Francisco, I helped a friend of mine (Ron Quintana) operate his fanzine Metal Mania (don't be confused, the name was re-appropriated by various larger publishing concerns at different times in the years since but none of them had any relationship to the original gangstas).
Those 25 things you should know about me memes circulating rarely interest me (honestly, I don't care that you have a collection of rare El Salvadoran currency). However, one thing that my friends know but regular readers may not is that I have a fairly eclectic background. Did you know that I used to hang around the art department's hot glass studio in college to blow glass? Did you know that I learned to program in Pascal when I was in college and hated it? Yea, yea, I don't care much anymore either. But anyway, back in the 80's I was friends with this Danish dude from LA who shared my interest in the underground heavy metal scene that was burgeoning, particularly in Britain ("New Wave of British Heavy Metal" AKA NWOBHM) and Europe. We used to trade records and demos (the first Def Leppard 3 song EP on 9" vinyl, I was tired of it so I traded him for a bunch of Tygers of Pan Tang and other crap I didn't own already). I think he, like myself, used to pick up copies of Melody Maker and Sounds at the local record store to read about what was going on overseas. Eventually, Kerrang! came out providing fuller coverage of the metal scene, complete with glossy pictures. But in the meantime back in San Francisco, I helped a friend of mine (Ron Quintana) operate his fanzine Metal Mania (don't be confused, the name was re-appropriated by various larger publishing concerns at different times in the years since but none of them had any relationship to the original gangstas).
Back in the day, Howie Klein was a muckety muck in the music industry, haunting the local clubs like The Old Waldorf and Mabuhay Gardens. Howie hooked us up with a show on KUSF. I dubbed the show Rampage Radio, it ran in the wee hours every Saturday night (right after Big Rick Stuart finished up his late night reggae show with those dudes from Green Apple Records on Clement Street). In between hurling insults at "album oriented rock" and big-hair metal bands (posers!), we played a lot of stuff you couldn't hear anywhere else. Among the many obscure noises we aired were demos from East Bay metalheads Exodus. Amazingly, Rampage Radio is still on the air. Well, that Danish kid and one of the guys I befriended from Exodus were Lars Ulrich and Kirk Hammett, respectively. In short order, they would be playing together in a band Lars named Metallica (after haggling with Ron about not taking that name for the 'zine).
I eventually lost interest in the metal scene (not enough innovation, too much sound-alike derivatives to keep me listening); even though the music from then is still on my playlist, my repertoire has broadened widely (talk to me about gypsy style string jazz, please). I've been peripherally in touch with friends from back then. Over the years, I'd go to a few Metallica shows but the guys are always mobbed at the backstage parties, there's not much of an opportunity to actually talk about anything. Anyway, we have little in common now. I develop software and crazy assed online services; they tour the world to perform in front of throngs. And I don't drink Jaegermeister anymore. In 2000, I introduced one of the friends I've stayed in touch with, Brian Lew, who also had a fanzine Back In The Day, to editors at salon.com (where I was working at the time). He contributed a great article expressing a sentiment that I shared, dismay at Metallica's war on Napster. I don't think I've actually talked to Lars in 15 years. After seeing news coverage of him ranting about how people (his most valued asset: his fans) where ripping him off, I'm not sure I wanted to. But I think we're all over that now, let's just play Rock Band and fuhgedaboutit.
So here we are decades later and Metallica hasn't just warped the music industry, they are the industry. They're up there with Elvis and the Beatles and all of that (except, barring Cliff Burton, they're not dead). Last week, Brian pings me that Q-Prime (Metallica's management company in New York) is trying to reach me. After a few phone calls, it turns out that Metallica is honoring a handful of us old-schoolers by inviting us to a big shindig in Cleveland for their Rock and Roll Hall of Fame induction next month. How cool is that?! I'm still kind blown away that this is really happening (am I being punkd??).
So, I may be leaving Technorati but I'm going to the Rock and Roll Hall of Fame! w00t! That tune keeps humming through my conscience, "...living in sin with a safety pin, Cleveland rocks! Cleveland rocks!" but the way it sounds in my head, it's ganked up, roaring from a massive PA and a wall of Marshall stacks. So now you know what my plans will be in a few weeks and now you've learned a dozen or so things about me (if not 25) that you may not have known before.
metallica rock and roll hall of fame metal kusf cleveland nwobhm
( Mar 12 2009, 12:22:51 PM PDT ) Permalink
Tuesday March 10, 2009
More Changes At Technorati (this time, it's personal)
![]() My post last week focused on some of the technology changes that I've been spearheading at Technorati but this time, I have a personal change to discuss. When I joined Technorati in 2004, the old world of the web was in shambles. The 1990's banner-ads-on-a-CPM-basis businesses were collapsed. The editorial teams using big workflow-oriented content management system (CMS) infrastructure (which I worked on in the 90's) were increasingly eclipsed by the ecosystem of blogs. Web 2.0 wasn't yet the word on everyone's lips. But five years ago, Dave Sifry's infectious vision for providing "connective tissue" for the blog ecosystem, tapping the attention signals and creating an emergent distributed meta-CMS helped put it there. Being of service to bloggers just sounded too good, so I jumped aboard.
My post last week focused on some of the technology changes that I've been spearheading at Technorati but this time, I have a personal change to discuss. When I joined Technorati in 2004, the old world of the web was in shambles. The 1990's banner-ads-on-a-CPM-basis businesses were collapsed. The editorial teams using big workflow-oriented content management system (CMS) infrastructure (which I worked on in the 90's) were increasingly eclipsed by the ecosystem of blogs. Web 2.0 wasn't yet the word on everyone's lips. But five years ago, Dave Sifry's infectious vision for providing "connective tissue" for the blog ecosystem, tapping the attention signals and creating an emergent distributed meta-CMS helped put it there. Being of service to bloggers just sounded too good, so I jumped aboard.
Through many iterations of blogospheric expansion, building data flow, search and discovery applications, dealing with data center outages (and migrations) and other adventures, it's been a long strange trip. I've made a lot of fantastic friends, contributed a lot of insight and determination and learned a great deal along the way. I am incredibly proud of what we've built over the last five years. However today it's time for me to move on, my last day at Technorati will be next week.
Technorati has a lot of great people, technology and possibilities. The aforementioned crawler rollout provides the technology platform with a better foundation that I'm sure Dorion and the rest of the team will build great things on. The ad platform will create an abundance of valuable opportunities for bloggers and other social media. I know from past experiences what a successful media business looks like and under Richard Jalichandra's leadership, I see all of the right things happening. The ad platform will leverage Technorati's social media data assets with the publisher and advertiser tools that will make Technorati an ad delivery powerhouse. I'm going to remain a friend of the company's and do what I can to help its continued success, but I will be doing so from elsewhere.
I want to take a moment to thank all of my colleagues, past and present, who have worked with me to get Technorati this far. The brainstorms, the hard work, the arguments and the epiphanies have been tremendously valuable to me. Thank You!
I'm not sure what's next for me. I feel strongly that the changes afoot in cloud infrastructure, open source data analytics, real time data stream technologies, location based services (specifically, GPS ubiquity) and improved mobile devices are going to build on Web 2.0. These social and technology shifts will provide primordial goo out of which new innovations will spring. And I intend to build some of them, so brace yourself for Web 3.0. It's times like these when the economy is athrash that the best opportunities emerge and running for cover isn't my style. The next few years will see incumbent players in inefficient markets crumble and more powerful paradigms take their place. I'm bringing my hammer.
( Mar 10 2009, 02:06:20 PM PDT ) PermalinkComments [4]
Wednesday March 04, 2009
Welcome to the Technorati Top 100, Mr. President
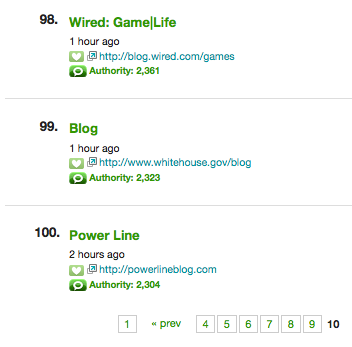 Since its inception just 6 weeks ago, the White House Blog has had a tremendous center of gravity. I noted the volume of links coming in to the White House Blog after the first week. This is an existential moment for the blogosphere because today the White House Blog has 3216 links from 2323 blogs. And so it's official: the White House Blog has reached the Technorati Top 100.
Since its inception just 6 weeks ago, the White House Blog has had a tremendous center of gravity. I noted the volume of links coming in to the White House Blog after the first week. This is an existential moment for the blogosphere because today the White House Blog has 3216 links from 2323 blogs. And so it's official: the White House Blog has reached the Technorati Top 100.
I find myself reflecting on what the top 100 looked like four years ago, after the prior presidential inauguration, and what it looks like today; the blogosphere is a very different place. Further down memory lane, who recalls when Dave Winer and Instapundit were among the top blogs? Yep, most of the small publishers have been displaced by those with big businesses behind them. Well, at least BoingBoing endures but Huffpo and Gizmo better watch out, here comes Prezbo.
technorati white house inauguration blog
( Mar 04 2009, 10:59:16 PM PST ) PermalinkNew Crawlers At Technorati
 A lot of changes are afoot at Technorati. Over the last year or so, we've been looking inward at the infrastructure and asking ourselves, "How can we do this better?". The data spigot that Technorati builds on was the first thing to focus on, it's a critical part in one leg of the back-end infrastructure tripod. The tripod consists of data acquisition, search and analytics Technorati; while the ping handling and queuing are relatively simple affairs the crawler is the most sophisticated of the data acquisition subsystems. It's proper functioning is critical to the functioning of the other legs; when it doesn't function well, search and analytics don't either (GIGO="garbage in/garbage out").
A lot of changes are afoot at Technorati. Over the last year or so, we've been looking inward at the infrastructure and asking ourselves, "How can we do this better?". The data spigot that Technorati builds on was the first thing to focus on, it's a critical part in one leg of the back-end infrastructure tripod. The tripod consists of data acquisition, search and analytics Technorati; while the ping handling and queuing are relatively simple affairs the crawler is the most sophisticated of the data acquisition subsystems. It's proper functioning is critical to the functioning of the other legs; when it doesn't function well, search and analytics don't either (GIGO="garbage in/garbage out").
As Dorion mentioned recently, we're retiring the old crawler. Why are we giving the old crawler getting an engraved watch and showing it to the door? Well, old age is one reason. The original spider is a technology that dates back to 2003, the blogosphere has changed a lot since then and we have a much better developed understanding of the requirements. The original spider code has presented a sufficient number of GIGO-related and code maintenance challenges to warrant a complete re-thinking. It contrasts starkly with the replacement.
- Data model
- There are a lot of ways to derive structural information out of the pages and feeds that a blog presents. The old spider used event driven parses, building a complex state as it went with flat data structures (lists and hashes). The new one uses the composed web documents to populate a well-defined object model; all crawls normalize the semi-structured data found on the web to that model.
- Crawl persistence
- The old spider was hard-wired to persist the aforementioned data structure elements to relational databases (sharded MySQL instances) while it was parsing, so that the flow of saving parsed data was closely coupled with parsing events, forsaking transactional integrity and consuming costly resources. The new spider composes and saves its parse result as a big discreet object (not collections of little objects in an RDBMS). This reduced the hardware footprint by an order of magnitude.
- Operational visibility
- Whether a blog's page structure was understood (or not), the feed was well formed (or not) or any of the many other things that determine the success or quality of a blog's crawl was opaque under the old spider. With the new spider, detailed metadata and metrics are tracked during the crawl cycles. This better enables the team to support bloggers and extend the system's capabilities.
- Unit tests
- Wherever you have complex, critical software you want to have unit tests. The old spider had almost no unit tests and was developed in a way that made testing the things that mattered most exceptionally difficult. The new spider was developed with a test harness upfront, it now has hundreds of tests that validate thousands of aspects of the code. The test are uniformly invoked by the developers and automatically whenever the code is updated (AKA under continuous integration).
Another change that we've made is to the legacy assumption that everything that pings is a blog. That assumption proved to be increasingly untenable as the ping meme spread amongst those who didn't really understand the difference between some random page and a blog, nefarious publishers (spammers) and other perpetrators of spings. Over 90% of the pings hitting Technorati are rejected outright because they've been identified as invalid pings. A large portion of the remainder are later determined to be invalid but we now have a rigorous system in place for filtering out the noise. We've reduced the spam level considerably (as mentioned in a prior post). For instance, there's a whole genre of splogs that are pornography focused (hardcore pictures, paid affiliate links, etc) that previously plagued our data; now we've eliminated a lot of that nonsense from the index.
Here are a pair of charts showing the daily occurrence of a particular porn term in the index.
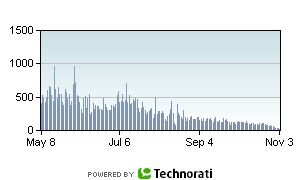
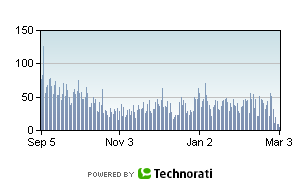
As you can see, that's an order of magnitude reduction; 90% of the occurrences of that term was spam.
So what's next for the crawler? We've got some stragglers on the old spider, we're going to migrate them over in the next few days. There are still a lot of issues to shake out, as with any new software (for instance, there are still some error recovery scenarios to deal with). But it's getting better all of the time (love that song). We'll be rolling out new tools internally for identifying where improvements are needed, ultimately we'd like to enable bloggers to help themselves to publish, get crawled, be found and recognized more effectively. And there are more changes afoot, stay tuned.
technorati web crawling software spam splogs
( Mar 04 2009, 08:31:16 PM PST ) PermalinkComments [2]



![[Valid RSS]](/images/valid-rss.png "Validate my RSS feed")