What's That Noise?! [Ian Kallen's Weblog]
 Wednesday March 04, 2009
Wednesday March 04, 2009
Welcome to the Technorati Top 100, Mr. President
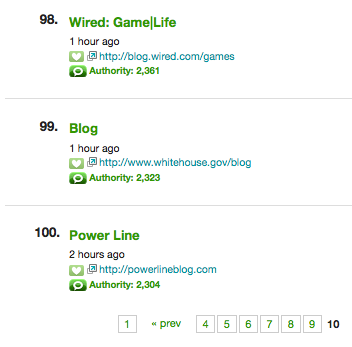 Since its inception just 6 weeks ago, the White House Blog has had a tremendous center of gravity. I noted the volume of links coming in to the White House Blog after the first week. This is an existential moment for the blogosphere because today the White House Blog has 3216 links from 2323 blogs. And so it's official: the White House Blog has reached the Technorati Top 100.
Since its inception just 6 weeks ago, the White House Blog has had a tremendous center of gravity. I noted the volume of links coming in to the White House Blog after the first week. This is an existential moment for the blogosphere because today the White House Blog has 3216 links from 2323 blogs. And so it's official: the White House Blog has reached the Technorati Top 100.
I find myself reflecting on what the top 100 looked like four years ago, after the prior presidential inauguration, and what it looks like today; the blogosphere is a very different place. Further down memory lane, who recalls when Dave Winer and Instapundit were among the top blogs? Yep, most of the small publishers have been displaced by those with big businesses behind them. Well, at least BoingBoing endures but Huffpo and Gizmo better watch out, here comes Prezbo.
technorati white house inauguration blog
( Mar 04 2009, 10:59:16 PM PST ) PermalinkNew Crawlers At Technorati
 A lot of changes are afoot at Technorati. Over the last year or so, we've been looking inward at the infrastructure and asking ourselves, "How can we do this better?". The data spigot that Technorati builds on was the first thing to focus on, it's a critical part in one leg of the back-end infrastructure tripod. The tripod consists of data acquisition, search and analytics Technorati; while the ping handling and queuing are relatively simple affairs the crawler is the most sophisticated of the data acquisition subsystems. It's proper functioning is critical to the functioning of the other legs; when it doesn't function well, search and analytics don't either (GIGO="garbage in/garbage out").
A lot of changes are afoot at Technorati. Over the last year or so, we've been looking inward at the infrastructure and asking ourselves, "How can we do this better?". The data spigot that Technorati builds on was the first thing to focus on, it's a critical part in one leg of the back-end infrastructure tripod. The tripod consists of data acquisition, search and analytics Technorati; while the ping handling and queuing are relatively simple affairs the crawler is the most sophisticated of the data acquisition subsystems. It's proper functioning is critical to the functioning of the other legs; when it doesn't function well, search and analytics don't either (GIGO="garbage in/garbage out").
As Dorion mentioned recently, we're retiring the old crawler. Why are we giving the old crawler getting an engraved watch and showing it to the door? Well, old age is one reason. The original spider is a technology that dates back to 2003, the blogosphere has changed a lot since then and we have a much better developed understanding of the requirements. The original spider code has presented a sufficient number of GIGO-related and code maintenance challenges to warrant a complete re-thinking. It contrasts starkly with the replacement.
- Data model
- There are a lot of ways to derive structural information out of the pages and feeds that a blog presents. The old spider used event driven parses, building a complex state as it went with flat data structures (lists and hashes). The new one uses the composed web documents to populate a well-defined object model; all crawls normalize the semi-structured data found on the web to that model.
- Crawl persistence
- The old spider was hard-wired to persist the aforementioned data structure elements to relational databases (sharded MySQL instances) while it was parsing, so that the flow of saving parsed data was closely coupled with parsing events, forsaking transactional integrity and consuming costly resources. The new spider composes and saves its parse result as a big discreet object (not collections of little objects in an RDBMS). This reduced the hardware footprint by an order of magnitude.
- Operational visibility
- Whether a blog's page structure was understood (or not), the feed was well formed (or not) or any of the many other things that determine the success or quality of a blog's crawl was opaque under the old spider. With the new spider, detailed metadata and metrics are tracked during the crawl cycles. This better enables the team to support bloggers and extend the system's capabilities.
- Unit tests
- Wherever you have complex, critical software you want to have unit tests. The old spider had almost no unit tests and was developed in a way that made testing the things that mattered most exceptionally difficult. The new spider was developed with a test harness upfront, it now has hundreds of tests that validate thousands of aspects of the code. The test are uniformly invoked by the developers and automatically whenever the code is updated (AKA under continuous integration).
Another change that we've made is to the legacy assumption that everything that pings is a blog. That assumption proved to be increasingly untenable as the ping meme spread amongst those who didn't really understand the difference between some random page and a blog, nefarious publishers (spammers) and other perpetrators of spings. Over 90% of the pings hitting Technorati are rejected outright because they've been identified as invalid pings. A large portion of the remainder are later determined to be invalid but we now have a rigorous system in place for filtering out the noise. We've reduced the spam level considerably (as mentioned in a prior post). For instance, there's a whole genre of splogs that are pornography focused (hardcore pictures, paid affiliate links, etc) that previously plagued our data; now we've eliminated a lot of that nonsense from the index.
Here are a pair of charts showing the daily occurrence of a particular porn term in the index.
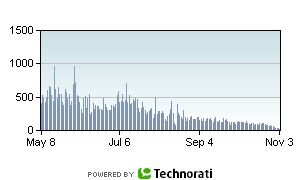
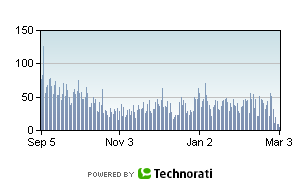
As you can see, that's an order of magnitude reduction; 90% of the occurrences of that term was spam.
So what's next for the crawler? We've got some stragglers on the old spider, we're going to migrate them over in the next few days. There are still a lot of issues to shake out, as with any new software (for instance, there are still some error recovery scenarios to deal with). But it's getting better all of the time (love that song). We'll be rolling out new tools internally for identifying where improvements are needed, ultimately we'd like to enable bloggers to help themselves to publish, get crawled, be found and recognized more effectively. And there are more changes afoot, stay tuned.
technorati web crawling software spam splogs
( Mar 04 2009, 08:31:16 PM PST ) PermalinkComments [2]



![[Valid RSS]](/images/valid-rss.png "Validate my RSS feed")